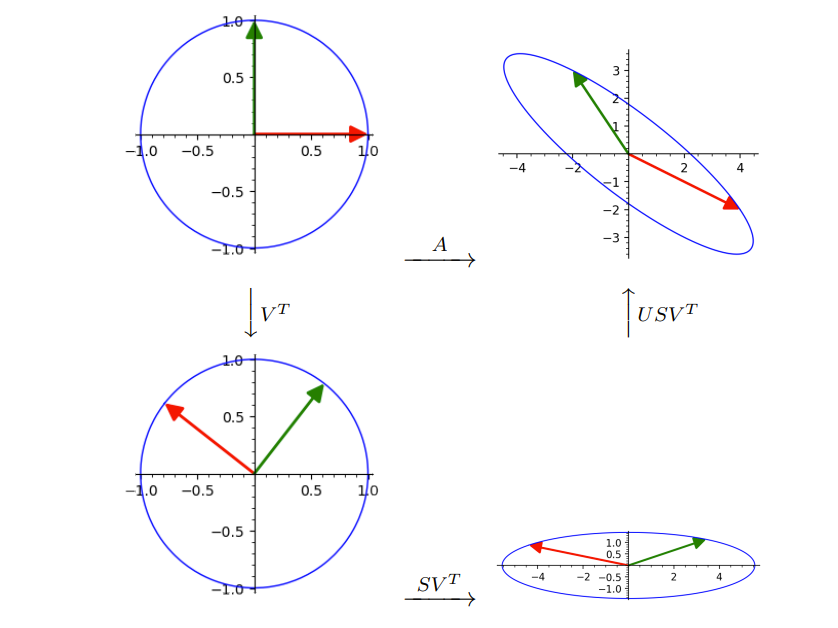
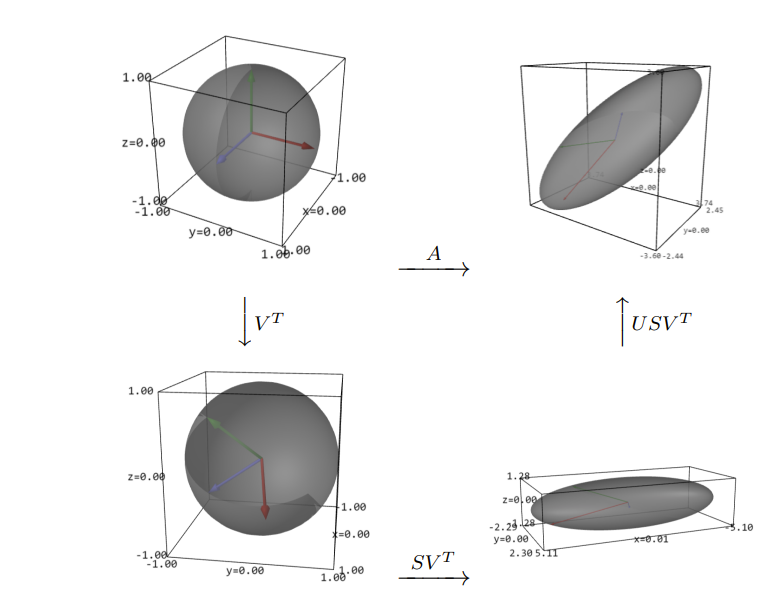
Note that \(A^TA\) is symmetric and \(\rank{(A)}=\rank{(A^TA)}\text{.}\) Let \(\rank{(A)}=r\text{.}\) Further
\begin{equation*}
\innprod{A^TAx}{x}=\innprod{Ax}{Ax}=\norm{Ax}^2\geq 0, \forall x\in \R^n\text{.}
\end{equation*}
Hence \(A^TA\) is a symmetric and semi-positive definite matrix. Hence all its eigenvalues are real and non negative. Let \(\lambda_1, \lambda_2,\ldots,\lambda_r\) be non zero eigenvalues of \(A^TA\) with \(\lambda_1\geq \lambda_2\geq\cdots\geq\lambda_r\text{.}\) The remaining eigenvalues of \(A^TA\) are \(\lambda_{r+1}=\lambda_{r+2}=\cdots=\lambda_n=0\text{.}\) Let us denote \(\lambda_i=\sigma_i^2\) for \(i=1,\ldots, n\text{.}\) Since \(A^TA\) is symmetric matrix, it is diagonalizable. Hence there exists an orthogonal eigenbasis \(v_1,\ldots,
v_n\) for \(\R^n\) of \(A^TA\text{.}\) Let \(A^TAv_i=\sigma_i^2v_i\text{.}\) This implies
\begin{align}
v_i^TA^TAv_i=\amp \sigma_i^2 \amp \text{ for } i=1,2,\ldots, r\tag{9.1.4}\\
v_i^TA^TAv_i=\amp 0 \amp \text{ for } i=r+1,\ldots, n\tag{9.1.5}
\end{align}
\begin{equation*}
v_k^TA^TAv_k=\innprod{Av_k}{Av_k}=0 \text{ for } i=r+1,\ldots,n\text{.}
\end{equation*}
This implies,
\begin{equation*}
Av_k=0 \text{ for } i=r+1,\ldots,n\text{.}
\end{equation*}
We define
\begin{equation}
u_i:=\frac{1}{\sigma_i}Av_i \text{ for } i=1,2,\ldots, r\text{.}\tag{9.1.6}
\end{equation}
We claim that \(\{u_1,\ldots,
u_r\}\) is an orthonormal set. For
\begin{equation*}
\innprod{u_i}{u_j}=u_i^Tu_j=\frac{1}{\sigma_i}(Av_i)^T\frac{1}{\sigma_j}Av_j =\frac{1}{\sigma_i\sigma_j}v_i^TA^TAv_j=\delta_{ij}\text{.}
\end{equation*}
Now we complete \(\{u_1,\ldots,
u_r\}\) to an orthonormal basis \(\{u_1,\ldots,
u_r,u_{r+1},\ldots, u_n\}\) of \(\R^n\text{.}\) Define
\begin{equation*}
U:=[u_1~\ldots~ u_r~u_{r+1}~\ldots~ u_n] \text{ and } V:=[v_1~\ldots~ v_r~v_{r+1}~\ldots~ v_n].
\end{equation*}
We claim that \(U^TAV=\sum\) and hence \(A= U\Sigma V^T\text{.}\)
\begin{align*}
U^TAV =\amp \begin{pmatrix} u_1^T\\\vdots \\ u_r^T\\u_{r+1}^T\\\vdots\\u_n^T\end{pmatrix}
A[v_1~\ldots~ v_r~v_{r+1}~\ldots~ v_n]\\
=\amp \begin{pmatrix} \frac{1}{\sigma_1}v_1^TA^T\\\vdots\\\frac{1}{\sigma_r}v_r^TA^T\\u_{r+1}^T\\
\vdots\\u_n^T\end{pmatrix}A[v_1~\ldots~ v_r~v_{r+1}~\ldots~ v_n]\\
=\amp \begin{pmatrix} \frac{1}{\sigma_1}v_1^TA^T\\\vdots\\\frac{1}{\sigma_r}v_r^TA^T\\
u_{r+1}^T\\\vdots\\u_n^T\end{pmatrix}[Av_1~\ldots~ Av_r~v_{r+1}~\ldots~ Av_n]\\
=\amp \diag(\sigma_1,\ldots,\sigma_r,0,\ldots,0)=\sum\text{.}
\end{align*}
Hence
\begin{equation*}
A=U\sum V^T\text{.}
\end{equation*}