In this chapter, we shall explore the concept of pricipal component analysis (PCA) which is somewhat similar to SVD. We shall look at what is similarity between PCA and SVD along with some applications.
Large datasets with a large number of features/variables are very common and widespread. Interpreting such a large datasets is very complex task. In order to interpret such datasets one requires a method that reduces the dimension/features drastically, at the same time most of the information in the dateset is preserved. The principal component analysis (PCA) is one of the most widely used dimensionality reduction techniques. The main idea of PCA is to reduce the dimensionality in the datasets while preserving much of the variability as much as possible. It does so by creating a new set of uncorrelated variables that successfully maximize the variance. Finding such new variables also known as principal components reduces the problem to solving an eigenvalue-eigenvector problem.
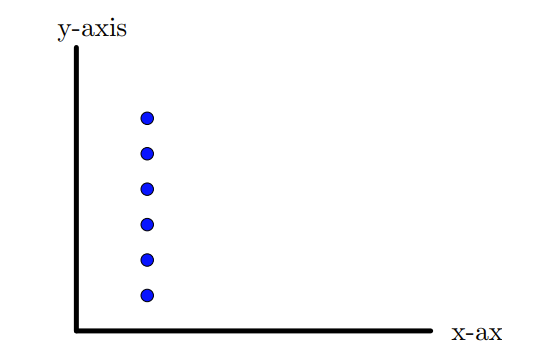
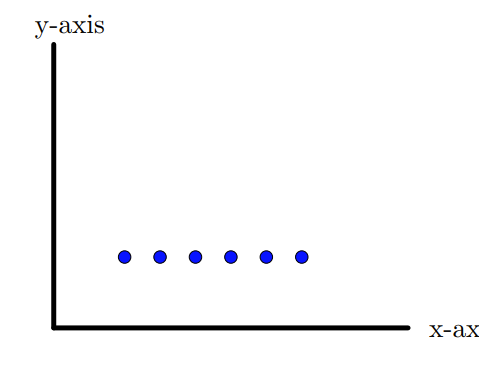
Let us look at the set of points in the plane, (data with two features) in the figure 10.1.1. In this case the data has maximum spread or variability along the \(y\)-axis. Thus if we project, the points onto the \(y\)-axis, the variability in the data can be captured. In particular, we can ignore the \(x\)-coordinates. On the other hand if we look at the set of points in the figure 10.1.2, maximum spread or variability lies along the \(x\)-axis. Thus if we project, the points onto the \(x\)-axis, the variability in the data can be captured. In particular, we can ignore the \(y\)-coordinates. Thus in these two examples, we are able to reduce the dimension by 1.
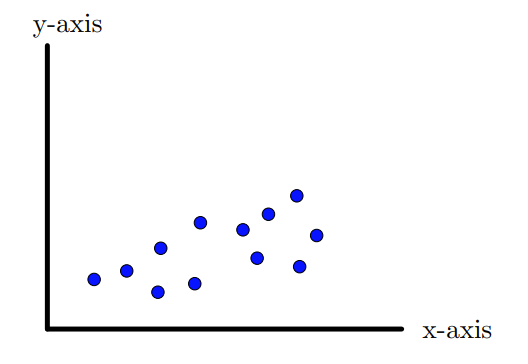
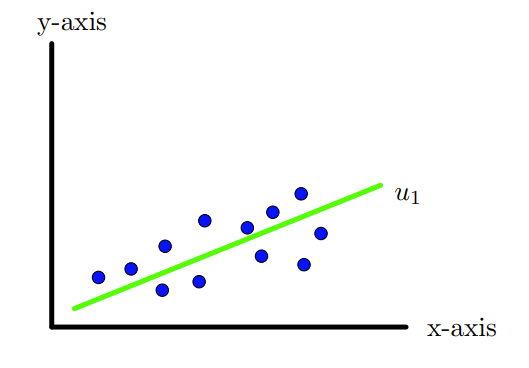
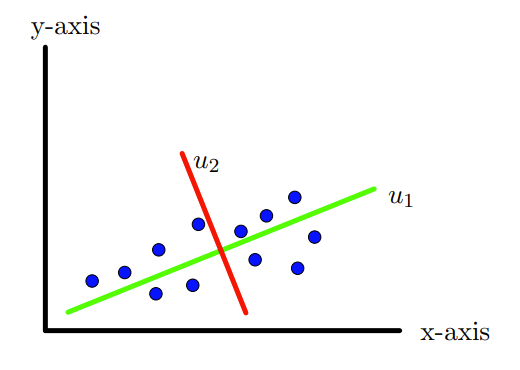
Now suppose we have 12 points as show in the Figure 10.1.3 again in \(\R^2\text{,}\) that is having two features/dimensions. The spread of this data seems to be not along \(x\)-axis but roughly along the axis as shown in the Figure 10.1.4, that is, along the vector \(u_1\text{.}\) So if we project these points on the line along \(u_1\) as shown in the Figure 10.1.4, we will have maximum spread or variation of the data. Thus \(u_1\) is the new axis along which the data has maximum variation.
Next if one carefully looks into the data points, one can see that the data also has some dispersion or variation along the line given by the direction \(u_2\) as shown in the Figure 10.1.5 and which is not captured by the line along \(u_1\text{.}\) In a way, we need to create another axis which is perpendicular to the 1st one.
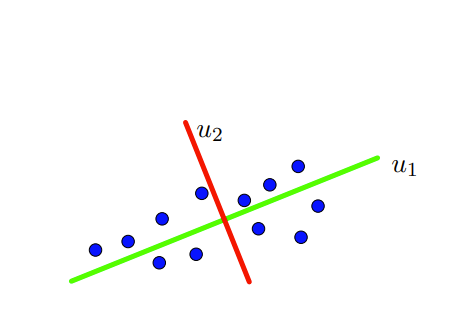
Thus we have two perpendicular coordinate axes or a new coordinates system along which all the variations in the data can be captured. In this case, maximum variation along \(u_1\) and second maximum along \(u_2\text{.}\) Here \(u_1\) is called the first principal direction and \(u_2\) is called the second principal direction. Thus we can work with new coordinate axes and forget about the original \(x\) and \(y\)-axes as show in the Figure 10.1.6. We can even rotate the new coordinate system that coincides with original \(x\) and \(y\)-axes.
The above two examples, geometrically explains the essence of PCA. The idea is to project the original high dimensional data to a new coordinate system and choose only first few coordinates axes also called principal components. How many principal components to be taken depends upon how much variation we wish to capture.
Let us assume that we have a dataset with \(n\) samples and each sample has \(d\) features. This data can be represented by a \(n\times d\) matrix, say \(X\text{.}\) Thus
Before we explain that in generality, let us look at what is meaning of projection of data in 2 dimension (that is in \(\R^2\)) on an unit vector. Suppose \(u=(a,b)\) is an unit vector and \(p_1=(x_1,y_1)\) be a point/vector in \(\R^2\text{.}\) Then
The length of the projection is \(p_1x_2+p_2x_2\text{.}\) If we have another point, say \(p_2 =(x_2,y_2)\text{,}\) then the projection of both these points can be captured as
Thus in general the projection of data \(X\) which is \(n\times d\) matrix onto a unit vector \(u_1=\begin{bmatrix}u_{11}\amp u_{12}\amp \cdots \amp u_{1d} \end{bmatrix} ^T\) is
Next we deal with the second issue in PCA, namely, ’variance’. For this we take the centered data \(X_c =X-\overline{X}\text{,}\) where \(\overline{X}=\frac{1}{d}\begin{bmatrix}x_{11}+x_{12}+\cdots+x_{1d}\\ x_{21}+x_{22}+\cdots+x_{2d}\\\vdots\\x_{1n}+x_{1n}+\cdots+x_{1n} \end{bmatrix}\text{.}\) The covariance of \(X\text{,}\) is given
\begin{equation*}
S ={ Cov}(X)=\frac{1}{n-1}{X_c}^TX_c\text{.}
\end{equation*}
Note that (i) \(S\) is symmetric and (ii) Semi-positive definite, all eigenvalues of \(S\) are non negative. Also \(S\) is orthogonally diagonalizable. In particular, there exists an orthogonal matrix \(U = \begin{bmatrix}u_1\amp u_2\amp \cdots \amp u_d \end{bmatrix}\) such that \(U^TSU = { diag }(\lambda_1,\cdots,\lambda_p)\text{.}\) What we wanted was to maximize the variance of projection of the data onto unit vector \(u\text{.}\) That is, we want to find an unit vector \(u\) such that the variance of \(X_cu\) is maximum. In other words,
\begin{align*}
\text{maximize }\amp \frac{1}{n-1}(X_cu)^T{X_cu}=\frac{1}{n-1}u^T(X_c^TX_c)u=u^TSu\\
\text{subject to } \amp \norm{u}=1\text{.}
\end{align*}
It turns out that the solution of this optimization problem is \(u\text{,}\) which is the eigenvector of \(S\text{.}\) Thus the variance of the projected data onto a unit vector is maximum if \(u\) happens to be an eigenvector of the covariance matrix \(S\text{.}\)
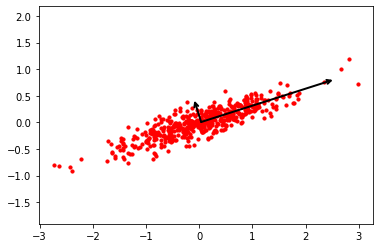
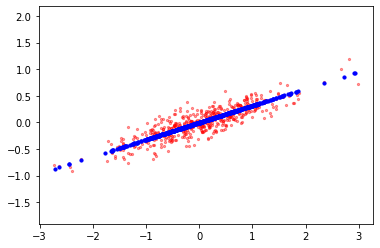
Note that \(S\) is of order \(d\times d\) which has \(d\) linearly independent eigenvectors. We arrange these eigenvector corresponding to the decreasing eigenvalues. That \(u_1\) is the eigenvector corresponding to the largest eigenvector \(\lambda_1\) and is called the first principal component. The eigenvector \(u_2\) corresponding to the second highest eigenvalue \(\lambda_2\text{,}\) is called the second principal component. Thus if we project data onto the second principal component that it will have second higher variance. Look at Figure 10.1.7 in which the data is plotted along with the principal components. The Figure 10.1.8, the data projected on the 1st component of PCA is plotted along with the data.
Next question is how many principal components, we should choose. This depends upon what percentage of variance of the data we wish to capture. Suppose we want to capture 90% variations, the we choose the 1st \(k\) components such that
Here \(V\) is called the loading matrix. The new data or transformed data \(Z=XV\text{.}\) Once we know the transformed data then we can construct the original data by \(X=ZV^T\text{.}\)
The eigenvalues of \(S\) are eigenvalues \(\lambda_1 =1.1620\) and \(\lambda_2=0.0696\text{.}\) The corresponding eigenvectors are \(u_1 = \begin{pmatrix}0.6894\\0.7243 \end{pmatrix}\) and \(u_2 = \begin{pmatrix}0.7243\\-0.689 \end{pmatrix}\text{.}\)